
TabBench V2: The new version of the open evaluation suite for tabular classification
Summary
Neuralk is releasing TabBench V2, the new version of its open evaluation suite for tabular classification 📊
LLMs have shown that diverse evaluations drive progress. In the tabular foundation model (TFM) space, the leading benchmarks today target different aspects of the problem. TabArena provides an AutoGluon-powered benchmark with tuning and ensembling, while LAMDA TALENT emphasises runtime efficiency alongside predictive performance. MultiTab broadens the lens with a rich set of auxiliary evaluation metrics, TabRed focuses primarily on numerically dominated datasets, and CARTE’s benchmark targets categorically dominated datasets.
As practitioners deploying tabular foundation models in production, we at Neuralk identified an unmet need: existing benchmarks did not adequately capture real enterprise use cases. To bring evaluation closer to the realities of business applications, we launched TabBench V1 last year with 50 carefully curated datasets. Today, we are significantly expanding that effort with TabBench V2, which brings together 189 datasets covering a wide spectrum of industries and practical machine learning tasks.
TabBench V2 includes 189 OpenML classification datasets spanning healthcare, finance and insurance, industry and science, retail and behavioral data, computer vision, gaming and synthetic data, social and public-sector applications, and more. Beyond accuracy, the gold standard of business metrics, TabBench V2 enables deeper analysis of model behavior, including calibration, robustness to class imbalance, across different industry verticals. The benchmark compares a broad range of approaches, from tree ensembles and tuned neural networks to the latest generation of pre-trained tabular foundation models.
Key Takeaways from the Benchmark
- A Shift in Performance: Tabular Foundation Models win 82.5% of head-to-head matchups against hyper-tuned tree ensembles, confirming that pre-trained in-context models now outperform traditional approaches on open data.
- The Front of the Pack: Seldon, TabICL v2 and TabPFN v3 emerge together at the top of the leaderboard, with near-identical overall performance.
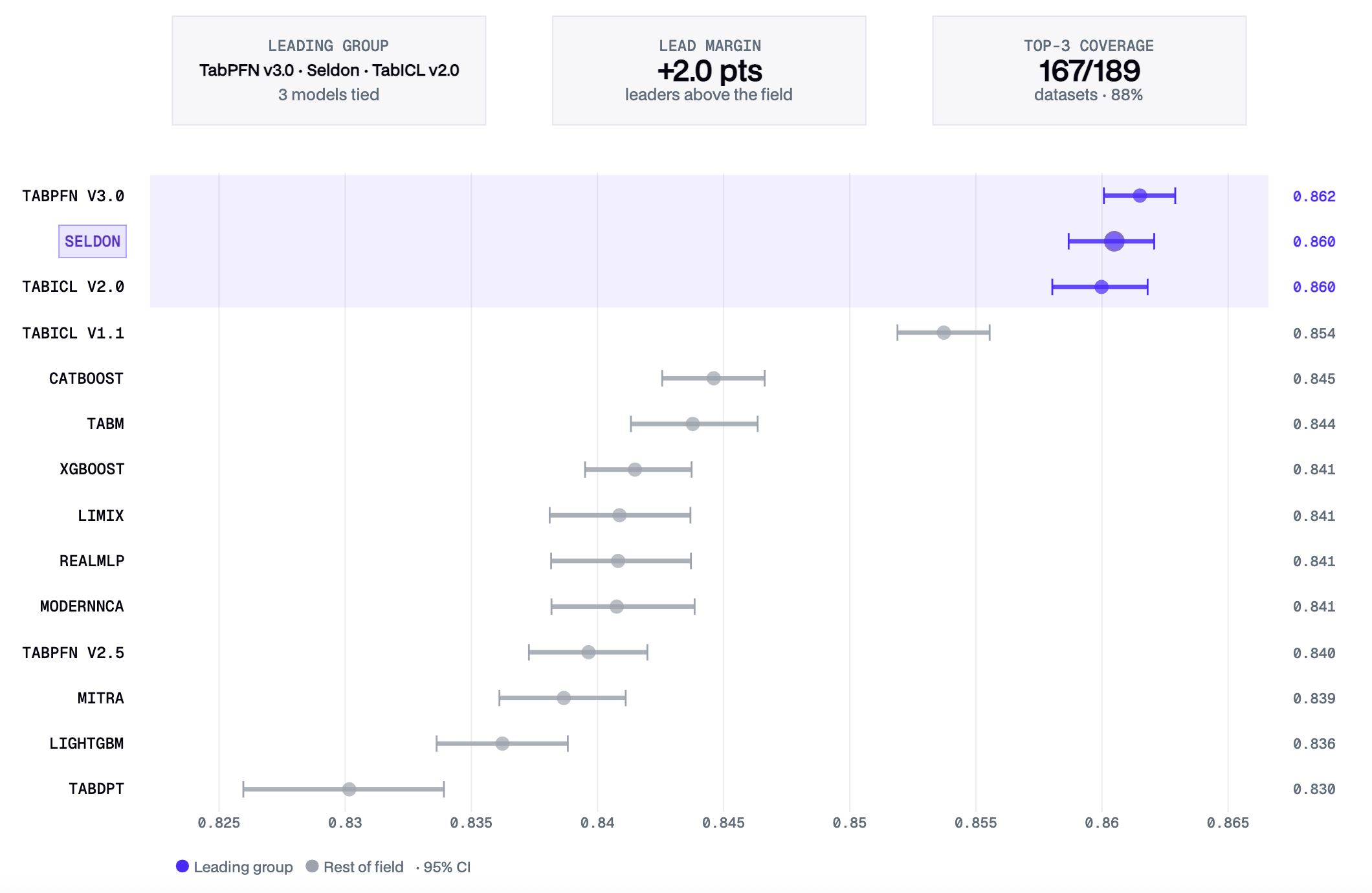
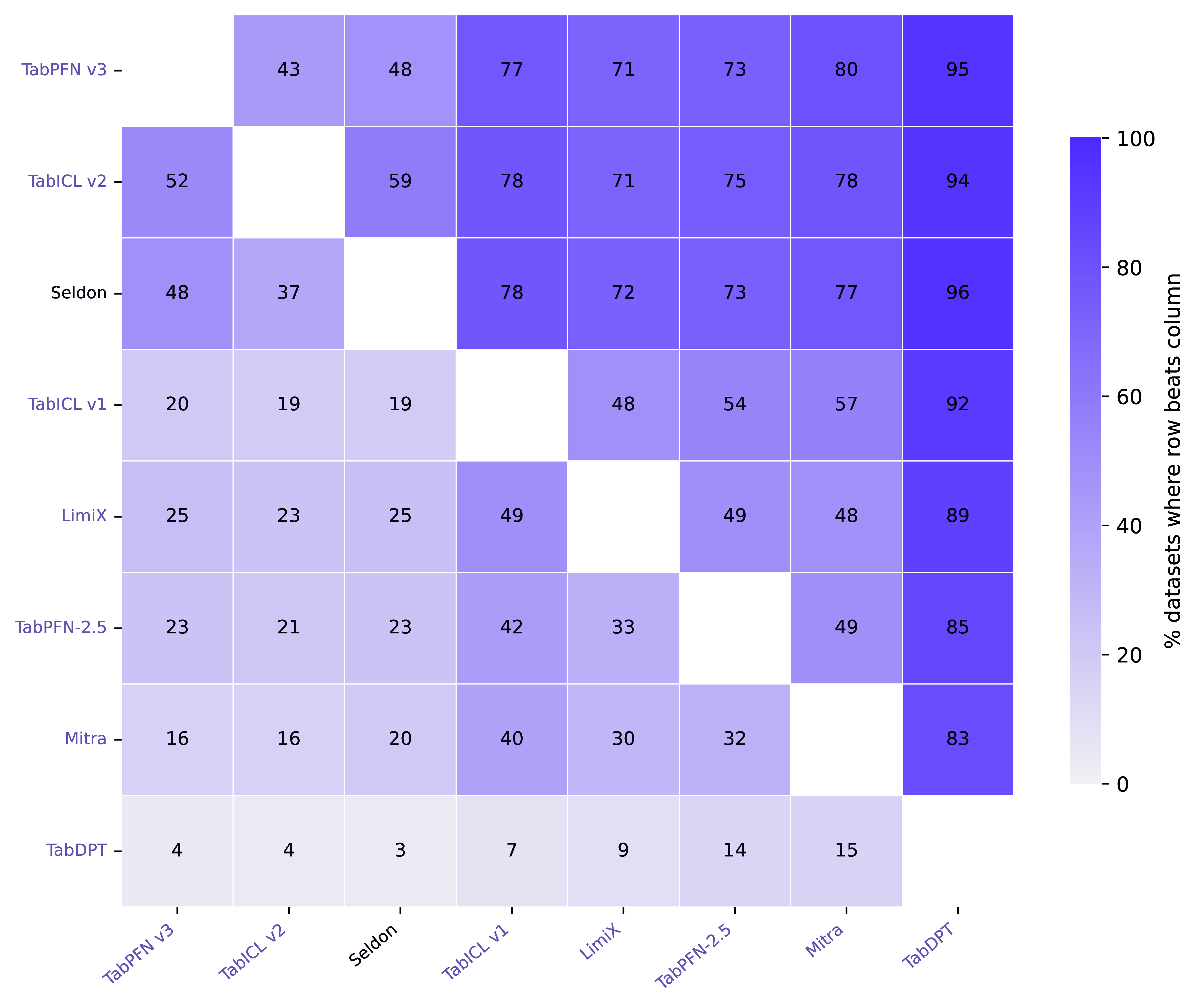
Beyond competitive accuracy, evaluating our model, Seldon, highlights its baseline operational reliability and speed across the suite:
- Robust Execution: Seldon successfully processes all datasets with a 0% failure rate, requiring no fallback mechanisms to traditional tree models.
- Single-Query Speed: For individual predictions, the model responds in under 100 milliseconds, even when referencing a large history of up to 100,000 rows.
- The only areas where classical models remain competitive are some mid-size binary tabular data (GBDT ensembles), and Games/Synthetic and Computer Vision tasks (tuned neural networks)
Your turn
Benchmarks are only as valuable as the community that uses them, challenges them, and helps them grow. Did any of the TabBench results surprise you? Does the leaderboard match what you see on your own datasets? We're building TabBench as a community resource, and we'd love your input.
→ Contribute a dataset: if you know of a classification dataset that captures a missing industry, challenge, or data modality, help us make TabBench even more representative.
pip install tabbench
→ Benchmark your model and see how your approach stacks up against the current leaderboard.
Check out all the visualisations and segmentations of all the performance results across 189 model-benchmark pairs at 🔗 : https://huggingface.co/spaces/Neuralk-AI/tabbench



