
Pioneering AI for structured data
At Neuralk, our research mission is to advance artificial intelligence specifically for structured (tabular) data — the vast and complex datasets that power real business decision-making yet remain underserved by today’s mainstream AI models.
Unlike models designed for unstructured inputs like text or images, our research focuses on the unique statistical and structural properties of tabular data to unlock high-accuracy predictions and real-world impact across industries such as commerce, finance, and healthcare.
Tabular foundation models: a new learning paradigm
Our core research centers around building Tabular Foundation Models (TFMs)
Pretrained AI systems that deliver instant predictions on structured datasets without the need for custom training or manual feature engineering. These models learn from millions of synthetic and real tabular datasets to internalize patterns and relationships that traditional machine learning (ML) and general-purpose large language models (LLMs) struggle to capture.

SUPPOrteD WOrkfloWS
PERFORMANCE BENCHMARK
SELDON
94.2%
XGBoost
88.7%
catboost
79.1%
RANDOM FOREST
75.4%
lightgbm
76.2%
tabicl
86.9%

Feature Versatility
Understand both numerical and categorical features across rows and columns.

High-Precision Accuracy
Produce highly accurate predictions for classification and regression tasks.

Instant Deployment
Eliminate lengthy training pipelines, enabling real-time inference at enterprise scale.

TabBench
Classification Leaderboard
Task
Model
Score
Product Classification
seldon
0.942
Product Classification
XGBOOST
0.887
Product Classification
Sonnet 4.1
0.645
Data deduplication
seldon
0.961
TabBench
Measuring what actually matters
To rigorously assess the performance of tabular AI models in real industrial settings, we develop TabBench — an open-source benchmarking framework that evaluates models with an industry lens, putting the focus on what really matters across industries.
TabBench enables standardized comparisons across models for tangible industry use cases like product classification, data deduplication, and more, empowering data scientists with robust measurements of model capability and generalization.
This benchmark initiative reflects our broader research philosophy: practical performance on realistic challenges matters as much as accuracy scores.
Bridging theory & Enterprise impact
Our research isn’t confined to theory; it’s designed for immediate business utility. Neuralk-AI’s models are applied to a range of enterprise workflows, including:
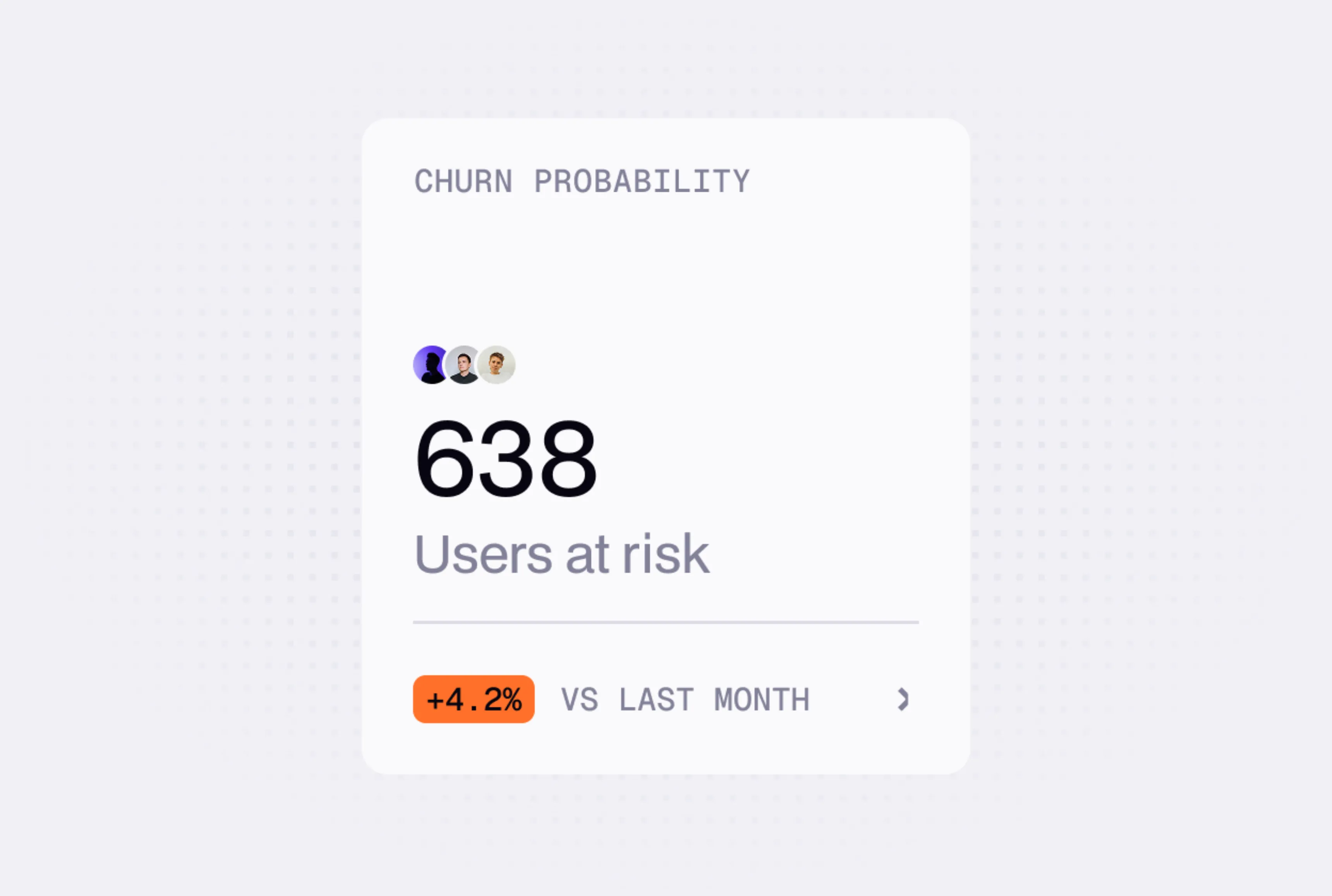
Churn Prediction
Predicting customer behavior ahead of time
Risk Scoring
Establishing risk profiles depending on behavior, and developing personalized recommendations
Demand Forecasting
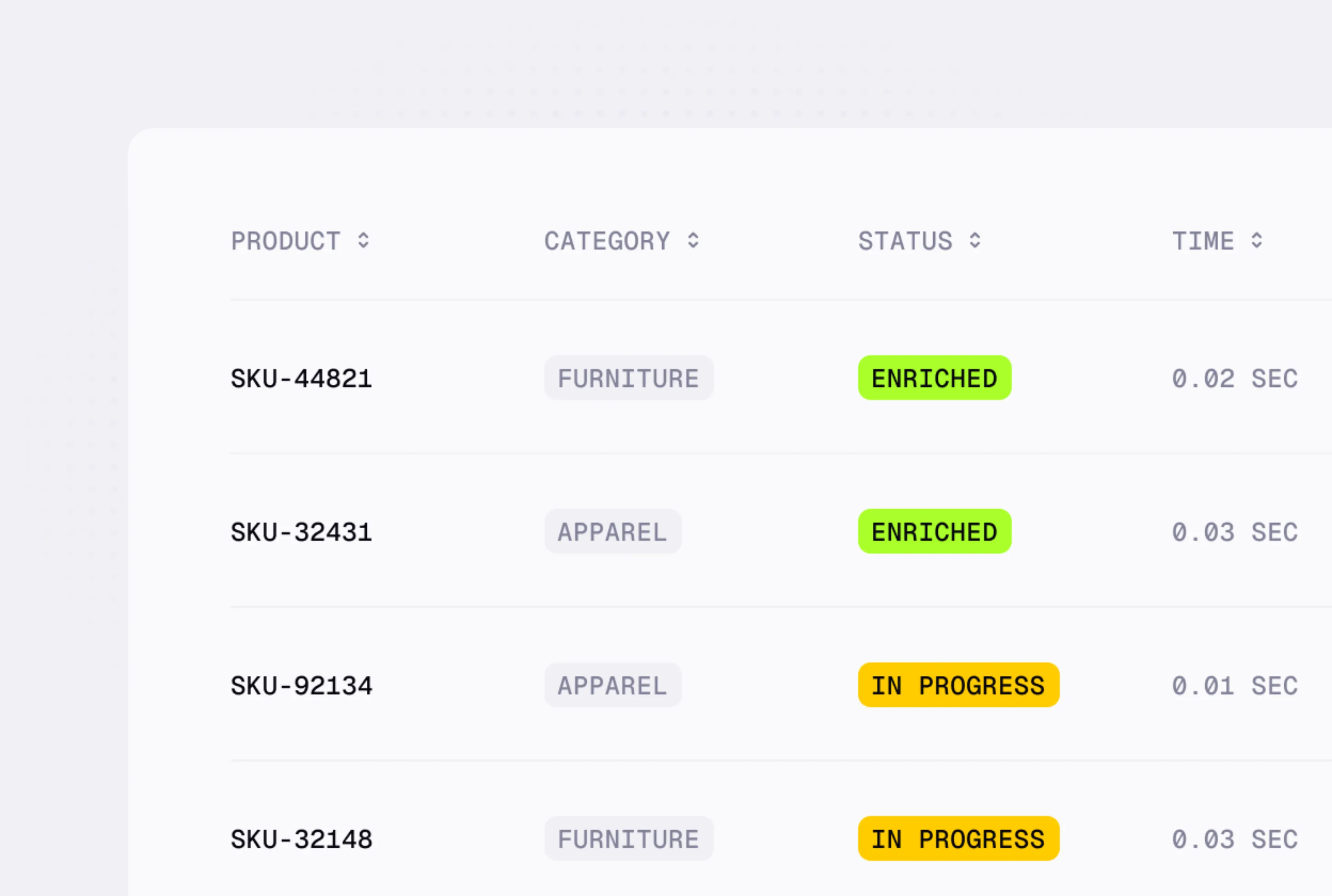
Automated catalog classification and attribute enrichment
These applications underscore how structural insights from tabular datasets can fuel better decision-making, automation, and business performance.
Collaborative & open research culture
Neuralk-AI actively contributes to the wider AI community through open benchmarks, technical blogs, and partnerships with academic and industry leaders. Our team’s work on tabular AI cuts across disciplines, building bridges between statistical learning, deep learning architectures, and practical systems that scale from research prototypes to production deployments.

Open source
Tabbench Hugging Face repo
Publications
Seldon: In-Context Learning for Tabular Data
blog
Why LLMs Fail on Tabular Data
Partnerships
Academic Research Collaborations

Making predictive intelligence ubiquitous for structured data
As structured data continues to define core business intelligence systems worldwide, Neuralk is committed to pushing the frontier of research in tabular AI. Our long-term vision is to make advanced predictive intelligence ubiquitous for any structured dataset that lives in rows and columns, ultimately transforming how businesses derive value from their most fundamental information sources.