
Seldon: A Tabular Foundation Model Built for the Industrial Frontier
Summary
For more than a decade, gradient-boosted decision trees have been the operational default for prediction on tables: credit approvals, fraud screens, demand forecasts, clinical risk scores. Large language models, for all the attention they have absorbed, did not change that. The shift is coming from a different direction. Tabular Foundation Models (TFMs) are neural predictors pre-trained once on synthetic tabular datasets and deployed at inference time as in-context predictors, with no per-task training.
Today we are unveiling the performance of Seldon, Neuralk's tabular foundation model. This post summarises the technical report: what TFMs actually approximate, how Seldon performs on our open-source benchmark TabBench, how it behaves on private industrial data and how we overcome the scaling issues and make Seldon actually usable by any practionner through our API.
Key takeaways
- Top tier on open data. On TabBench's 189 classification datasets, Seldon, TabPFN v3, and TabICL v2 form a statistically indistinguishable leading cluster (mean ranks 3.3–3.6), sitting clearly ahead of every tuned tree ensemble and every other open TFM.
- The industrial frontier is not the academic frontier. On 22 private industrial problems across five sectors, the clean separation between TFMs and tree ensembles disappears. Tuned XGBoost and LightGBM stay competitive everywhere.
- Seldon is the clear industrial leader. It takes the best mean rank on the industrial pool (2.21 of 5), edging out tuned XGBoost (2.27) and beating every other foundation model outright. Among the top-tier TFMs the margin is decisive: Seldon wins 50% of the pool head-to-head, against 18% for TabPFN v3 and 9% for TabICL v2, beating TabPFN v3 on 18 of 22 problems and TabICL v2 on 15 of 22.
- Built to scale. The Seldon API runs a full forward pass over 15M rows × 540 features (roughly 8 billion cells) in under 12 minutes and is faster than any other public TFM service on every measured grid point.
- Read the full technical report
What a TFM actually approximates
Classical tabular learning recovers the posterior predictive p(y*|x*, D) one dataset at a time: pick a hypothesis class, fit its parameters on D from scratch, use the fit as a point approximation. GBDTs, MLPs, and table-by-table transformers all live in this regime; hyperparameter tuning, ensembling, and feature engineering are all ways to compensate for the fact that no information from any other table is being used.
The Prior-Fitted Network (PFN) formulation reverses the order of operations. Inference is amortized: a single network is pre-trained once to imitate the posterior predictive across an entire distribution of synthetic tables,
%7D%20%20E_%7B(x*%2C%20y*)%20~%20D%7D%20%20%5B%20%E2%88%92%20log%20f_%CE%B8(y*%20%7C%20x*%2C%20D)%20%5D.png)
where p(D) is a programmatic generator of synthetic tables. At convergence, the forward pass of the network is the Bayes posterior predictive under that prior [Muller et. al., 2022]. Prediction on a new task collapses to a single in-context inference call, no gradient updates required.
In practice, designing a TFM involves three choices:
- The prior p(D). It fixes the function class the model can represent at test time. The field is converging on structural causal models: random DAGs over features and target, with a random functional mechanism on each edge. It has moved from dense MLP-shaped SCMs toward sparser, more realistic graph-based priors with quality filters.
- The architecture. The current generation (Seldon, TabPFN v3, TabICL v2) factorizes attention into three stages: a column transformer that builds a semantic latent per column, a row transformer that compresses each row into a single embedding, and an in-context block that attends across row embeddings to predict. This cuts inference cost over
nrows and d columns from O(n²d + nd²) of naïve cell-attention to roughly O(n² + nd²), which is what makes million-row contexts feasible.
- The context. A PFN is fed labelled in-context examples. In production, where context windows are bounded and not every training row is equally informative, context becomes a design lever: subsample, retrieve neighbours, or choose wisely the context that mimicks an expert-based soft inductive bias. This degree of freedom has no equivalent in the fit-one-model-per-table regime and remains largely under-explored.
TabBench: crossing the tree-ensemble frontier
TabBench is our open evaluation suite, now spanning 189 OpenML classification datasets across retail, healthcare, finance, energy, and more. Every model runs through the same pipeline: stratified 5-fold splits, model-aware preprocessing, ROC-AUC as the optimisation target. Tunable baselines (XGBoost, CatBoost, LightGBM, RealMLP, TabM, ModernNCA) get a fix budget for hyperparameter tuning per dataset; TFMs are evaluated strictly zero-shot with their default hyper-parameters. Seldon is called through the public API with default settings.
What stands out is how tightly the three leaders are packed. Seldon, TabPFN v3, and TabICL v2 land within 0.4 AUC points of one another (0.904, 0.906, 0.902) and within a hair on accuracy (0.861, 0.862, 0.859): all not significantly different despite the strong statistical power of a 189-dataset benchmark, and all clearly detached from the next cluster of TFMs (TabPFN-2.5, LimiX, TabICL v1, Mitra). The win-rate picture separates them only slightly: TabPFN v3 collects the most strict wins (27.5%), TabICL v2 follows (22.8%), and Seldon (14.8%). The broader verdict is unambiguous: three foundation models sit clearly ahead of every tree ensemble and every other TFM on this benchmark.
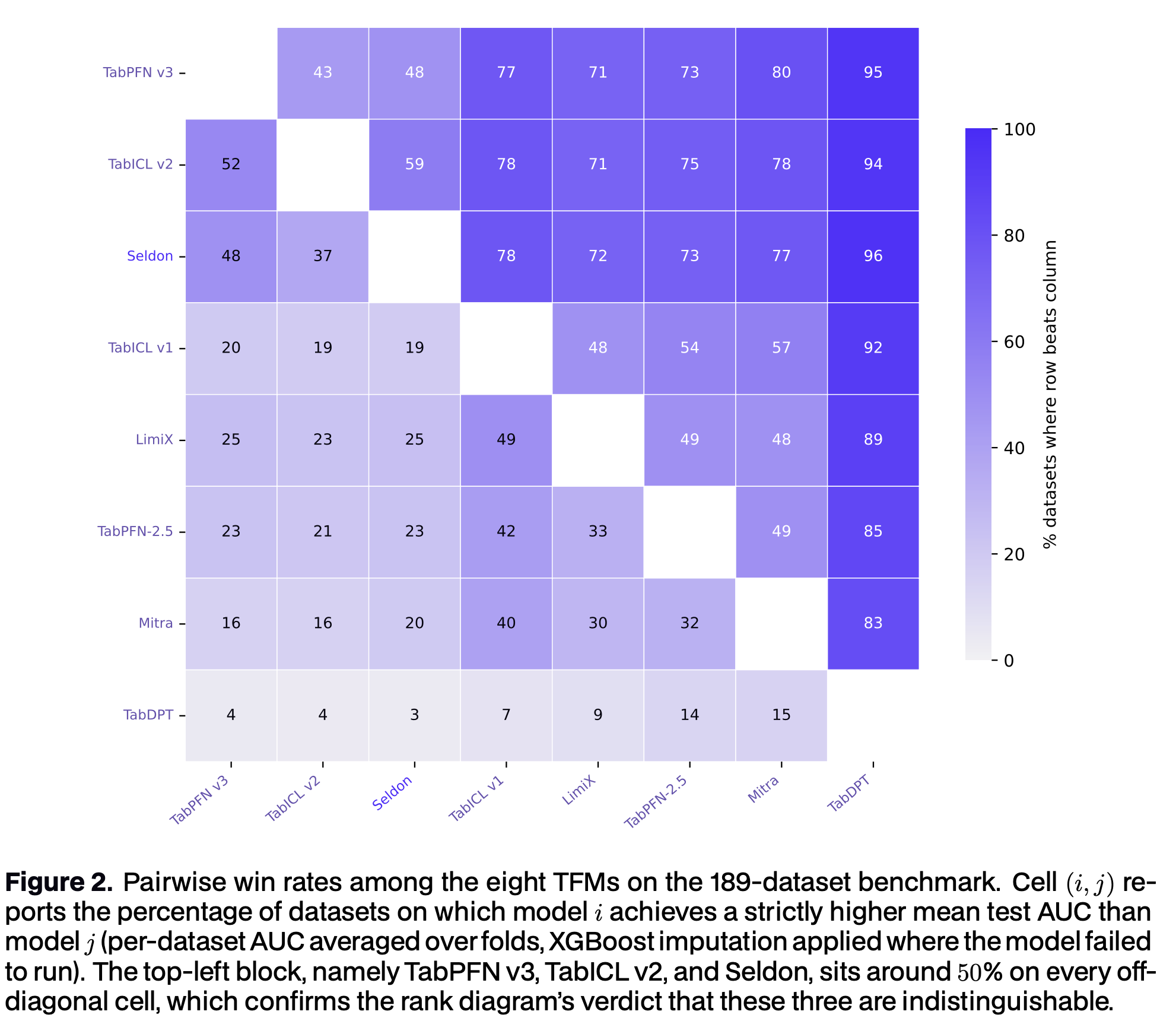
For practitioners, the implication is that the choice within the top tier is no longer about peak accuracy on open data: the three leaders are equivalent there. It is about coverage, latency, and how the model behaves on data that does not look like a public sanitised benchmark.
The industrial benchmark: where the story changes
Academic benchmarks are pre-cleaned. Industrial datasets are not. They bring heterogeneous high-cardinality schemas, pervasive and informative missingness, late and noisy labels, temporal (not random) train/test boundaries, class prevalences down to fractions of a percent, and signal-to-noise ratios where the predictive component is a sliver of a feature's variance. The synthetic priors that power public TFMs capture almost none of this faithfully: synthetic categoricals carry no semantics, synthetic missingness is MCAR/MAR rather than informative, imbalance is uniform, and there is no mechanism for drift or adversarial dynamics.
We evaluated the leading model of each family: the two strongest tuned tree ensembles (XGBoost, LightGBM) and the three top-tier TFMs (Seldon, TabPFN v3, TabICL v2) on a portfolio of 22 anonymized production problems across five sectors: retail (SKU-level return-rate prediction), behavioural (churn across seven base-rate setpoints), equity (cross-sectional return prediction under temporal shift), transportation (rail late-rate classification from SNCF open data), and energy (DPE-V2 building performance certification from ADEME).
The picture inverts the academic one. The strict TFM-vs-tree separation disappears; tuned XGBoost and LightGBM are competitive on every sector. And yet Seldon still takes the best mean rank on the pool at 2.21 of 5, narrowly ahead of XGBoost (2.27), with LightGBM (3.27), TabICL v2 (3.55), and TabPFN v3 (3.71) trailing. In head-to-head, Seldon beats XGBoost on 12 of 22 problems and LightGBM on 14 of 22.
Within the TFM family, Seldon wins outright on 50% of the industrial pool, against 18% for TabPFN v3 and 9% for TabICL v2 : beating TabPFN v3 on 18 of 22 problems and TabICL v2 on 15 of 22.
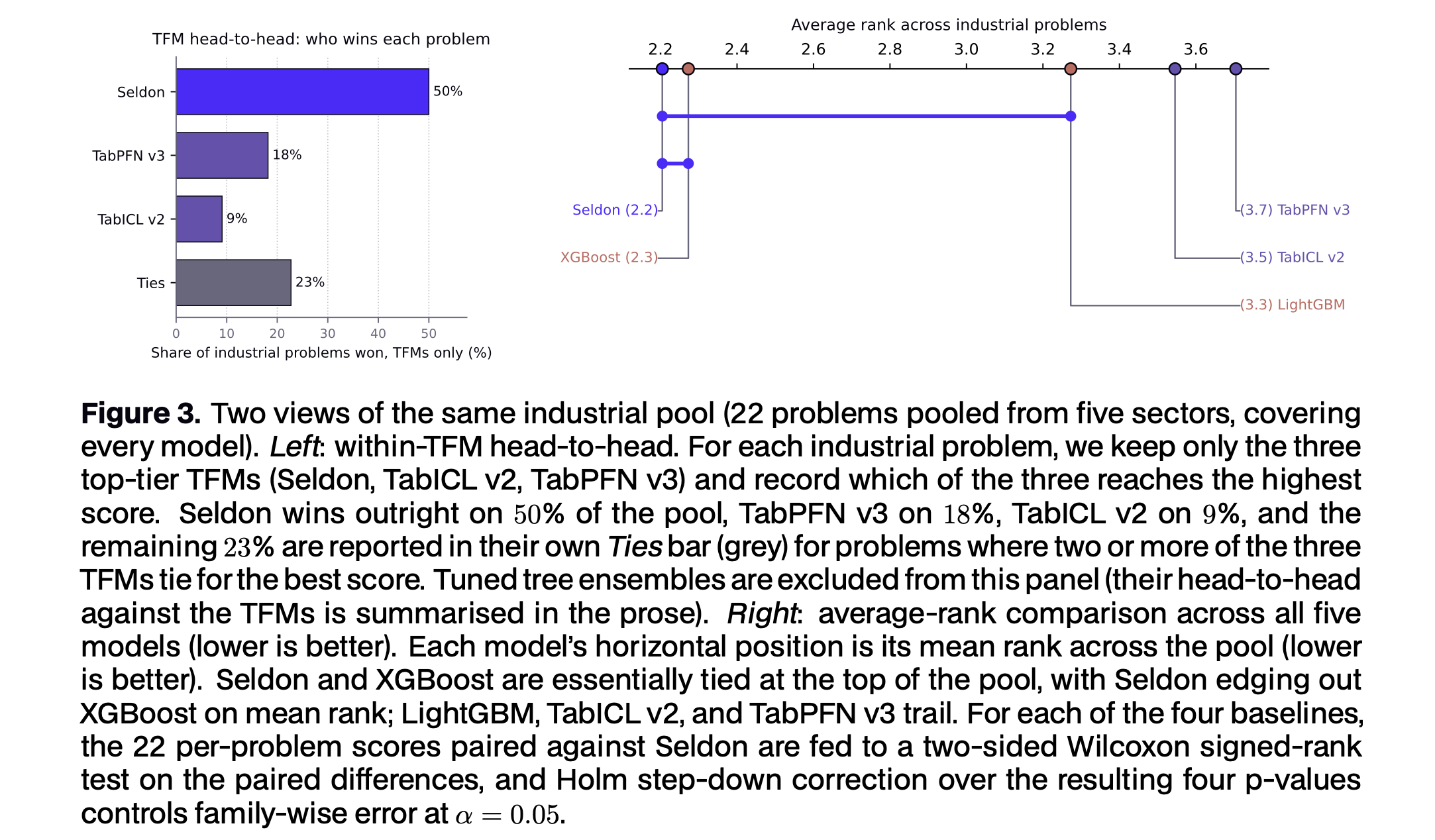
This is the result that motivates Seldon as an industrially focused TFM. Topping an academic leaderboard is table stakes for the top tier now; holding the lead once the data is joined, partial, drifting, and imbalanced is the harder and more relevant test.
Serving: the Seldon API
Accuracy is not all, when it comes to deployment. TFM architectures are quadratic in either row count or cell count and require a GPU on the inference path, which makes them hard to adopt. Seldon absorbs that into a hosted, scikit-learn-compatible endpoint with a free tier. A complete integration is three lines:
from neuralk import SeldonClassifier
model = SeldonClassifier()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
On its free-tier, the Seldon API completes a 15M-row forward pass (540 features ~8B cells) in under 12 minutes, and on the small-context regime it is faster than the only other public TFM service on every measured grid point. The estimator dispatches between classification and regression from the target and composes with scikit-learn pipelines, cross-validation, and metric stacks. The same SDK targets an on-premise endpoint for workloads where input transfer dominates.
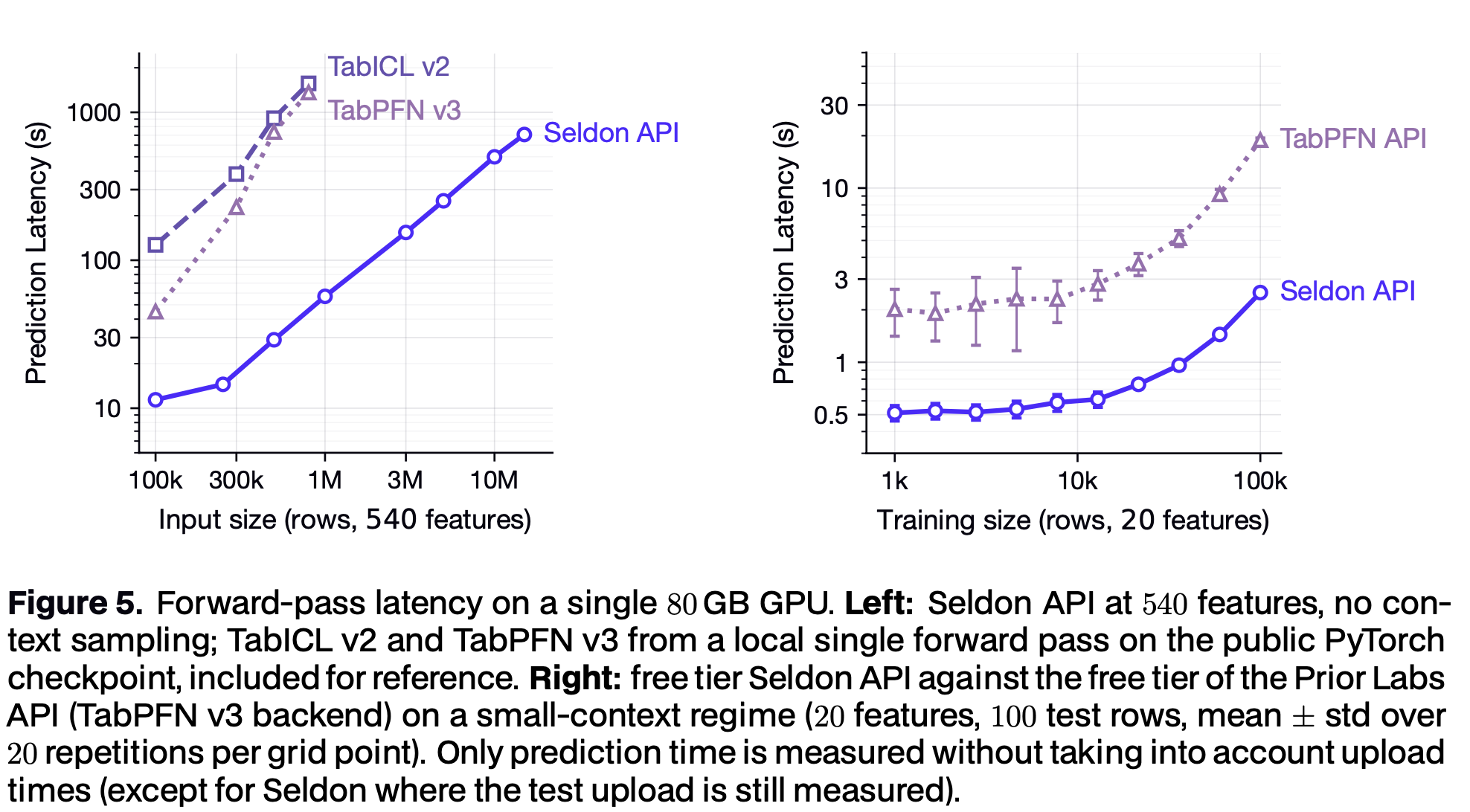
Every benchmark number above was produced by calling this API with default parameters.
What's next
Tabular foundation models are still a young field with more open questions than settled answers. What actually makes a synthetic prior effective remains poorly understood, despite bearing directly on generalisation. The quadratic time complexity of the dominant architectures constrains the scale of pretraining data and, with it, the prospect of genuinely large-scale tabular pretraining. And native modelling of temporal data, the regime most industrial problems actually live in, is largely untouched.
Seldon is our entry into that frontier, and the part that matters most to us is the one the academic leaderboard under-tests: behaviour on real industrial data. You can start testing it for free.
→ Try the Seldon API
→ Explore TabBench and benchmark your own model
→ Want to know more about research at Neuralk?
→ Read the full technical report
References
[Muller et. al., 2022] Samuel Müller, Noah Hollmann, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. Transformers can do Bayesian inference. In ICLR, 2022.



